














July 18, 2026
|
5 min read

Published: June 4, 2026

Blazingly fast way to build, track and deploy your models!
Generative AI has rapidly moved from experimentation to execution and is now embedded across products, operations, and customer experiences. However, as enterprises scale adoption, a structural issue is emerging: AI usage is growing faster than the mechanisms required to control cost. What begins as a contained pilot quickly expands into multiple teams building independently, applications invoking multiple models, and agentic workflows executing multi-step reasoning. The result is not just higher spend, but increasingly unpredictable and compounding costs across the organization.
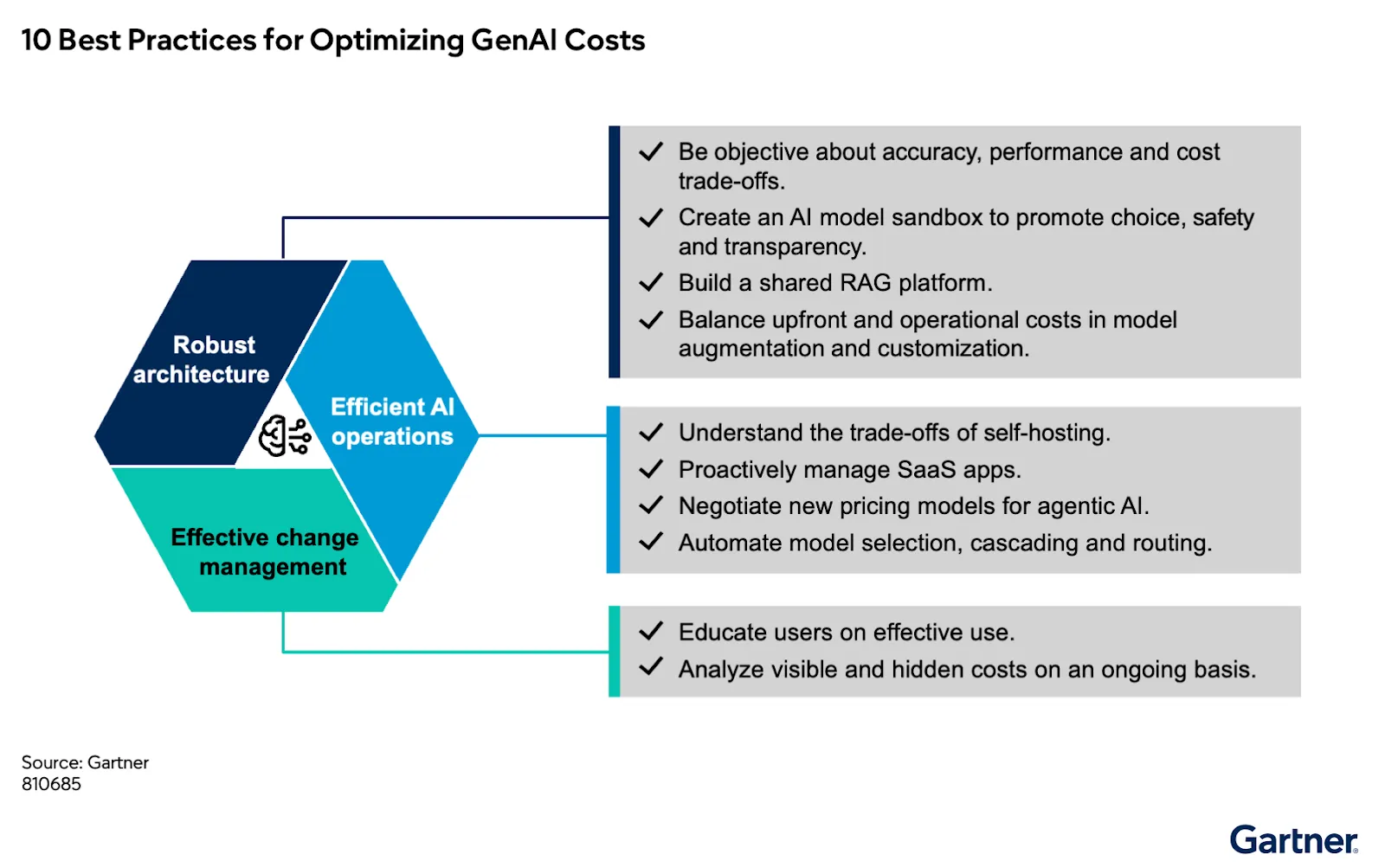
This challenge is highlighted in Gartner “10 Best Practices for Optimizing Generative and Agentic AI Costs” , which examines how architectural decisions and lack of operational discipline drive cost overruns at scale. As the report notes, “Through 2028, at least 50% of GenAI projects will overrun their budgeted costs due to poor architectural choices and lack of operational know-how.” This is not a tooling problem—it is fundamentally an architectural and operating model failure.
This shift is explored in Gartner “10 Best Practices for Optimizing Generative and Agentic AI Costs” , which focuses on how enterprises must rethink cost, governance, and operational control as AI systems move into production.
TrueFoundry is mentioned in this report in the context of AI gateways—an emerging control layer for managing cost, reliability, and governance across AI workloads.
Gartner highlights the scale of the challenge clearly: “Organizations transitioning from GenAI pilots to production experience a rude awakening when it comes to costs. Creating a production-ready GenAI system can be orders of magnitude more expensive than running a pilot.” This marks the inflection point—AI cost becomes a runtime problem, not a build-time concern, driven by how systems are orchestrated, governed, and operated at scale.

To understand the problem, it is important to break down how AI systems behave at scale.
1 Inference Becomes the Dominant Cost Layer
Unlike traditional systems, AI incurs cost every time it is used.
Gartner highlights this shift:
“Through 2028, the aggregated costs of model inference will be at least 70% of the total model lifetime costs…”
This fundamentally changes how cost must be managed.
2 Agentic Workflows Multiply Cost per Request
Modern AI systems are not single-step.
A single request can trigger:
This creates non-linear cost expansion.
3 Fragmented Adoption Drives Inefficiency
In most enterprises:
This leads to:
4 Lack of Runtime Governance Leads to Cost Sprawl
Without centralized control:
This is where cost becomes unmanageable at scale.
The recommendations in the Gartner point to a clear shift.
This is not about better models.
It is about controlling how models are used in production.
Key practices include:
1 Centralized Access to AI Systems
A single control layer to manage all model and tool interactions.
2 Intelligent Model Routing
Selecting models dynamically based on cost, latency, and performance.
3 Governance and Policy Enforcement
Applying quotas, limits, and guardrails across all usage.
4 End-to-End Observability
Tracking usage, performance, and cost at a granular level.
5 Cost Optimization Mechanisms
Reducing redundant inference through caching and reuse.
Gartner formalizes this shift:
“A new category of tools called AI gateways can help control costs by enforcing policies… and by providing features such as caching and model routing to reduce costs.”
This defines a new layer:
the AI control plane
We believe that the direction Gartner outlines points to a clear requirement:
a centralized control layer that governs how AI is used across the enterprise.
TrueFoundry has been mentioned in this report as part of this emerging AI gateway ecosystem.
TrueFoundry operates at the layer where AI usage occurs—and where cost is generated.
1 From Reactive Tracking to Proactive Control
Instead of:
TrueFoundry enables:
2 Dynamic Optimization at Runtime
3 Full Visibility Across AI Systems
4 Governance at Enterprise Scale
5 Enterprise-Ready Deployment
This shifts the operating model from:
“What is our AI spend?”
to
“Are we using AI efficiently—and should this request even be executed?”
Generative AI is entering its second phase.
The first phase was about access.
The next phase is about control and economics.
At the same time, pricing models are evolving:
“By 2030, at least 40% of enterprise SaaS spend will shift toward usage-, agent- or outcome-based pricing.” This makes cost:
Organizations that introduce control at the runtime layer will:
Final Perspective
Gartner is defining generative AI cost as a systems-level challenge rooted in runtime behavior—not model selection. Because at scale:
The enterprises that succeed will not be those that adopt AI faster.
They will be the ones that introduce:
control, governance, and economic discipline into how AI systems operate.
The advantage will not come from access to models—
but from control over how those models are used.
Explore Further
�� Read the full Gartner report
�� Learn more about TrueFoundry: https://www.truefoundry.com
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact.
Gartner, 10 Best Practices for Optimizing Generative and Agentic AI Costs, By Arun Chandrasekaran et. al, 20 March 2026
GARTNER is a trademark of Gartner, Inc. and/or its affiliates.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


You can optimize generative AI costs by using the right model for each task and avoiding unnecessary usage. For example, simple tasks do not require large and expensive models, so choosing smaller ones can reduce spend. In addition, keeping prompts focused helps avoid extra token usage that does not add value. Similarly, limiting response length prevents paying for unnecessary output. Over time, regularly tracking usage makes it easier to identify where costs are increasing and take corrective action.
You can reduce LLM costs by cutting down on long prompts and repeated queries. Since longer inputs increase token usage, keeping them concise helps control costs. At the same time, repeated queries without caching can lead to avoidable spending. Using smaller models for basic tasks is another effective way to reduce costs without impacting performance. Overall, maintaining control over both input and output length ensures more efficient and predictable usage.
An AI gateway helps optimize costs by controlling how different AI models are used. It routes requests to the most cost-effective model based on the task, so simple queries do not end up using expensive models. This prevents unnecessary spend and improves efficiency. With TrueFoundry, the AI gateway goes a step further by giving teams a unified layer to connect, observe, and govern AI usage across applications. It also provides clear visibility into token usage, enables smart routing, and helps enforce limits to keep spending under control.
Yes, you can use generative AI for free through limited plans offered by providers. These plans are useful for testing and small-scale usage. However, they come with restrictions on usage and features. Once usage increases, you will need to move to paid plans.
Generative AI is expensive because it requires high computing power for every request. Large models run on costly infrastructure, which increases overall expenses. Costs also come from embeddings, integrations, and repeated workflows. This makes the total cost higher than just token usage.
The best practices for AI cost optimization include using the smallest effective model and reducing unnecessary usage. Keeping prompts clear and output limited helps control token usage. Monitoring usage regularly helps identify cost-heavy areas. Reducing repeated tasks and optimizing workflows also improves efficiency.
LLM inference cost is affected by model size, token usage, and request frequency. Larger models cost more because they require more computing power. Longer prompts and outputs increase token usage and cost. Frequent or multi-step requests can quickly increase overall expenses.
Token usage impacts AI costs by determining how much you are charged per request. Every input and output is measured in tokens. Longer prompts and responses lead to higher costs. Managing token usage carefully helps keep overall spending under control.
The cost of running LLMs in production includes token usage, infrastructure, and system-related expenses. You also need to account for storage, monitoring, and integrations. Token costs are often only a part of the total spend. As usage grows, these additional costs increase significantly.
Agentic AI is a system where AI performs tasks through multiple steps and decisions. It affects costs by increasing the number of model calls required to complete a task. Each step adds to token usage and compute cost. This makes it more expensive than single-step AI interactions.






The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





