














July 18, 2026
|
5 min read

Published: June 1, 2026
Blazingly fast way to build, track and deploy your models!
Many teams that ship their third or fourth production agent notice the same pattern: a large fraction of the code in every agent file is infrastructure, not agent logic. Retry wrappers, credential loading, tool registries, session state, sandboxing — copy-pasted from the previous agent with small drift. One increasingly common solution is a managed agent layer that owns those concerns once, exposes a narrow API to agent code, and routes the actual work through the gateways the platform already runs. This post defines the layer, walks its five components, and shows how the AI gateway and MCP gateway plug into it — culminating in Anthropic's April 2026 Managed Agents release as one example of the same general separation.
Wednesday at Northwind. Devi, senior engineer on the platform team, opens the PR for the fourth agent her team has shipped this quarter — a release-notes generator wired into the deploy bot. The diff is 312 lines. She knows from experience that maybe 30 of those lines are the agent's actual reasoning loop. The remaining ~280 are the same five things she has now written four times: a tool registry that loads MCP server configs from two places, retry logic with exponential backoff that doesn't quite match the previous agent's version, credential loading from a mix of environment variables and the secrets manager, session state pushed to Redis with a TTL that was tuned by guess, and a try/except cascade that distinguishes rate limits from auth errors from provider outages.
At four agents in production, that is roughly 1,120 lines of infrastructure code spread across the team, every copy subtly drifted. When the provider's rate-limit policy changes next month, four PRs are needed to fix it. When the credential-rotation procedure changes, four more. The agent logic itself — the part that decides which tool to call when — is the smallest and least-touched part of every file. The infrastructure around it is what burns the engineering time.
The fix is not better copy-paste discipline. The pattern this post argues for is a layer between agent code and the runtime that owns the infrastructure once, and lets the agent code be agent code. It is one architecture among several — workflow graphs and durable-execution engines are valid alternatives — but it is the one that has emerged most clearly in recent provider-managed-agent products, and the one TrueFoundry's gateway primitives slot into directly.
Here is what the entangled version of one of Devi's agents looks like, abbreviated. The full file is around 200 lines; what is below is the first 35.
Python — naive agent, infrastructure mixed with logic (abbreviated)
import os, time, random, json, yaml, redis
import anthropic, openai
from github import Github
class CodeReviewAgent:
def __init__(self):
# Credential loading — three different patterns across our four agents
self.anthropic_key = os.environ.get("ANTHROPIC_API_KEY") \
or self._load_from_vault("anthropic")
self.openai_key = os.environ.get("OPENAI_API_KEY") \
or self._load_from_vault("openai")
self.github_token = self._load_from_vault("github-pat") # different vault path
# Tool registry — drifted from review-agent-v2's version
with open("mcp_servers.yaml") as f:
self.tools = self._build_tool_registry(yaml.safe_load(f))
# State store — TTL was 30min in v2, 1h here, nobody remembers why
self.redis = redis.Redis.from_url(os.environ["REDIS_URL"])
self.session_ttl = 3600
self.anthropic = anthropic.Anthropic(api_key=self.anthropic_key)
def run(self, pr_id):
# Retry loop — slightly different in every agent file we own
for attempt in range(5):
try:
response = self.anthropic.messages.create(...)
break
except anthropic.RateLimitError:
time.sleep(2 ** attempt + random.random())
except anthropic.APIStatusError as e:
if e.status_code >= 500:
time.sleep(2 ** attempt + random.random())
else:
raise
# ... 170 more lines like this. The actual reasoning loop starts around line 130.
None of this is the agent. It is the substrate the agent runs on. And every agent the team ships has its own slightly-drifted copy of all of it, because there is no layer that owns it.
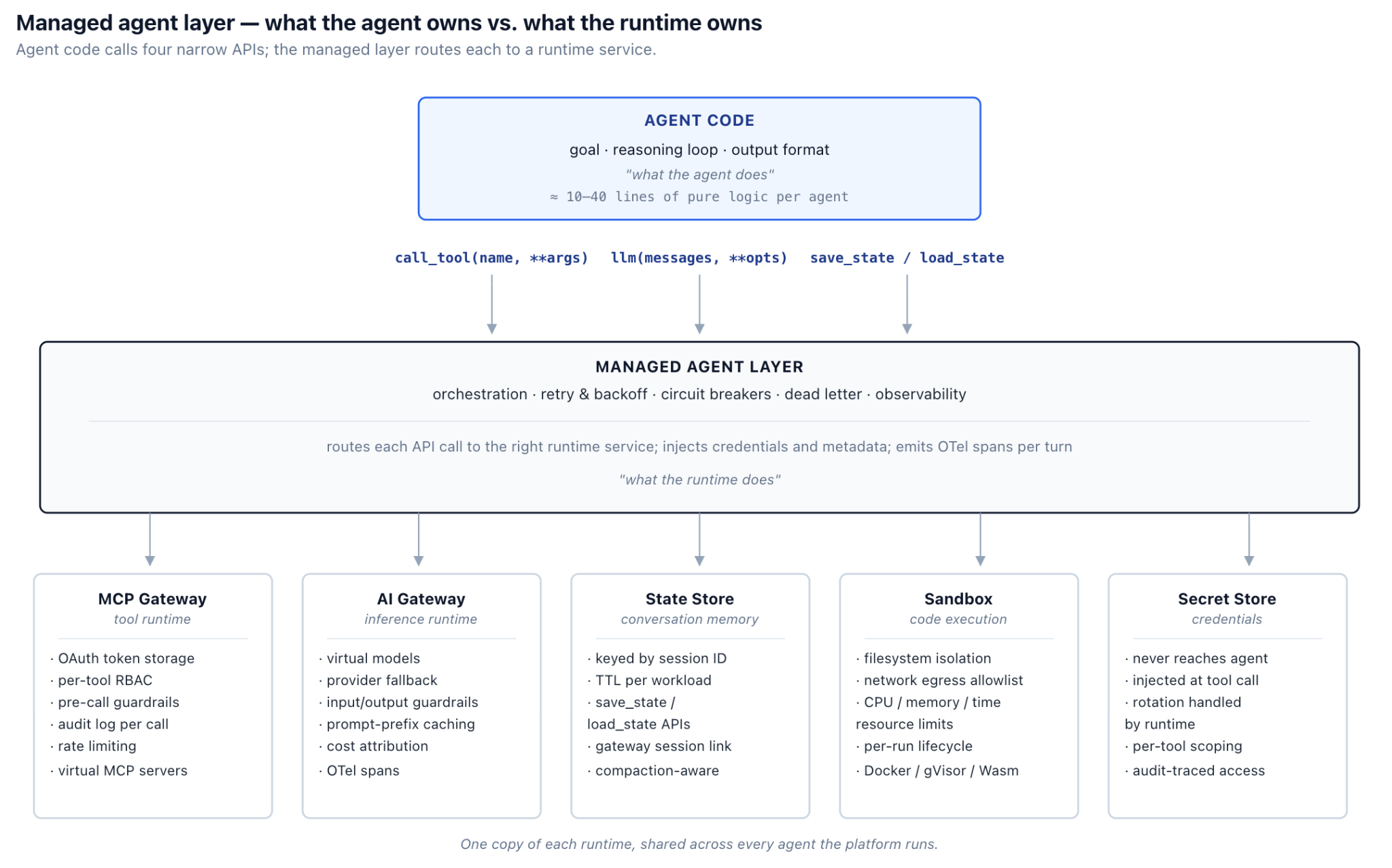
The managed agent layer is the abstraction that owns the substrate. It exposes three narrow APIs to agent code, and nothing else:
Python — the API surface the managed layer exposes to agent code
class ManagedAgent:
# Tool invocation — routes through the MCP gateway, handles auth/RBAC/audit.
# Credentials are fetched from the secret store and injected by the runtime
# at call time; agent code references tools by logical name, never by token.
async def call_tool(self, name: str, **args) -> dict: ...
# Model inference — routes through the AI gateway, handles routing/guardrails/cost
async def llm(self, messages: list, **opts) -> str: ...
# Session state — keyed under the conversation ID, runtime owns persistence
async def save_state(self, key: str, value: object) -> None: ...
async def load_state(self, key: str) -> object | None: ...Agent code is responsible for three things and three things only: the goal (what the agent is trying to accomplish), the reasoning loop (when to call which tool and how to interpret results), and the output format (what the agent returns when it finishes). Everything else — auth, retries, sandboxing, state persistence, observability — belongs to the runtime. Notably, there is no get_credential method: secrets do not flow through agent code, even by request.
Here is the same code-review agent on the managed layer. The PR is now smaller than its old test file:
Python — same agent on the managed layer, pure logic
from truefoundry.agent import ManagedAgent
class CodeReviewAgent(ManagedAgent):
"""Reviews a pull request against the repo's style guide."""
async def run(self, pr_id: str):
diff = await self.call_tool("github.get_pr_diff", pr_id=pr_id)
review = await self.llm([
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": diff},
])
await self.call_tool("github.post_review", pr_id=pr_id, body=review)
return {"status": "ok", "review_length": len(review)}
No credentials. No retry loop. No state code. No provider SDK. The infrastructure that used to live in every agent file now lives once, in the runtime, where it can be tested, versioned, and rolled out independently.
Orchestration. In a managed-runtime architecture, the runtime owns the agent loop — invoking the agent's reasoning step, parsing the model output for tool calls, dispatching them, feeding results back, and detecting termination. (Workflow-graph and durable-execution styles invert this — the agent owns the graph and the runtime provides primitives; the tradeoff is more explicit control flow at the cost of more agent-side machinery.) Stop conditions are non-trivial in either model: explicit "done" from the model, an output that no longer requests a tool, a hard turn-cap to bound runaway loops, a stuck-detector that fires when the agent has been calling the same tool with the same arguments three turns in a row.
Sandboxing. A coding agent that runs tests to verify its own changes needs an isolated execution environment — no access to the host filesystem outside a designated workspace, no outbound network except to the AI gateway and registered MCP servers, hard CPU/memory/wall-clock limits. The sandbox is per-run and disposable.
State management. Between turns the conversation history, agent scratchpad, intermediate tool results, and any progress markers have to live somewhere. The runtime provides save_state and load_state keyed under the session ID, with a TTL appropriate to the workload.
Credential injection. Agent code never sees a raw secret. The runtime fetches credentials from a secret store and injects them at the moment of a tool call — typically as an Authorization header the agent code never gets to read. The same mechanism handles rotation: when a credential is rotated, the next tool call uses the new value with no agent-code change.
Retry and error handling. Exponential backoff for rate limits, circuit breakers for provider outages, a dead-letter queue for runs that fail after exhausting retries. The runtime classifies each error — transient, permanent, auth — and applies the right policy. Agent code sees either a successful result or a final, classified exception, not the raw retry state.
The managed layer's llm() API does not call a provider SDK directly. It routes through the AI gateway, which owns the provider-coupling problem on the agent's behalf.
Python — what an agent does NOT do, vs. what the runtime does for it
# What agent code looks like with the managed layer:
review = await self.llm(messages, model="claude-sonnet-4-6")
# What the runtime does on the agent's behalf, via the gateway:
# 1. Resolves "claude-sonnet-4-6" through the virtual-model config — could
# be routed to a different provider entirely based on cost or availability.
# 2. Applies the team's input guardrails (PII scrubbing, prompt-injection
# detection) before the call leaves the platform.
# 3. Picks an upstream account by load and rate-limit headroom; falls
# back to a configured alternate on provider outage.
# 4. Streams the response back; applies output guardrails and emits OTel
# spans with the team/app metadata from the previous post in this series.
# 5. Computes per-trace cost at span close, books it against the team budget.The decoupling is structural. Agent code does not know — and does not need to know — whether its call went to OpenAI, Anthropic, or a self-hosted model. When the platform team adds a new provider, switches a model, or rolls out a new guardrail, no agent PRs are required. The agent's contract is the API surface, not the upstream.
The same pattern applies to tools. Agent code calls call_tool() with a logical name; the MCP gateway resolves it to a specific MCP server, injects the right OAuth token, applies RBAC, runs pre-execution guardrails, logs the call, and returns the result.
Python — agent code calling a tool through the MCP gateway
diff = await self.call_tool("github.get_pr_diff", pr_id="4127")
issues = await self.call_tool("linter.check", diff=diff, ruleset="strict")
await self.call_tool("slack.post_message", channel="#code-review", text=summary)Behind that surface, the gateway holds the OAuth tokens for every MCP server the platform supports, mapped to the calling user or service identity. It refreshes them when they expire. It enforces RBAC at the tool granularity — "this agent can call github.get_pr_diff but not github.create_pr" — independently of what the agent's code says. It logs every invocation with arguments, return values, and the calling agent and session IDs, creating a centralized audit log for tool use across the platform (subject to the usual realities — log pipelines can drop, sample, or lag). TrueFoundry's MCP Gateway adds a virtual-MCP-server abstraction on top: a single logical endpoint that aggregates tools from several physical MCP servers, so an agent's tool list does not change when backend implementations change.
The contract for agent code is the same as the AI gateway contract: call the API with a logical name, get a result, and let the runtime handle the credentials.
When an agent executes code — a coding agent that runs tests, a data agent that runs Python on a CSV, a tooling agent that runs an arbitrary shell command — that code needs to run in something isolated from the host. The three serious options in May 2026, with cold-start numbers as rough order-of-magnitude (real numbers depend heavily on image size, warm pools, snapshotting, and node state):
The choice is a function of tenancy and latency. A single-tenant agent that runs a long coding session per task gets Docker — cold-start cost is paid once and amortizes across hundreds of code executions. A multi-tenant platform serving untrusted agent code gets gVisor — the shared kernel of plain containers is a real concern when the code is arbitrary. A latency-sensitive workload that runs a sandbox per tool call (a calculator tool, a regex tool) gets Wasm — paying a one-second cold start per invocation is intolerable when the invocation itself is twenty milliseconds.
None of this is the agent's concern. The runtime exposes "execute this code, here is the result" and chooses the right sandbox for the workload class.
Where the agent's working memory lives between turns has three real options:
Most production agents end up using a combination: gateway session for the conversation rollup and observability, external store for the agent's explicit scratchpad and progress markers, in-context for the most recent few turns. The runtime exposes save_state and load_state as the agent-facing API regardless of which backend it routes to.
Anthropic's Managed Agents, in public beta since April 9, 2026 (beta header: managed-agents-2026-04-01), can be read as an example of the same general separation between agent logic and execution infrastructure. Their "meta-harness" architecture exposes components that map onto most of what this post describes: an orchestrated agent loop, sandboxed code execution (initially Anthropic-hosted, with self-hosted sandboxes added in a subsequent release), session continuity with stateful pause-and-resume, credential management for external systems, and observability via traces. Anthropic's own framing is brain-and-hands: Claude plus the harness runs on Anthropic infrastructure (the brain); the sandbox where shell commands and code execute is the hands.
For teams building agents on a single provider, Anthropic's product is the simplest path — the harness is on by default for every Claude API account, and the API surface is the new managed-agents beta header. For teams running agents across multiple providers, or with their own sandboxing and tooling requirements, the same pattern can be assembled from gateway primitives: an AI gateway as the inference runtime (multi-provider, with cost attribution and budget enforcement carrying over from the earlier posts in this series), an MCP gateway as the tool runtime, and a sandbox and state-store layer the platform team owns. TrueFoundry's AI Gateway and MCP Gateway are the two of those layers we ship as products; the orchestration and sandbox layers above them are deliberately pluggable, because they are where workload-specific decisions live.
Is the managed agent layer just a framework like LangGraph or AutoGen?
Frameworks like LangGraph and AutoGen are agent-loop libraries — they own the orchestration component of what this post calls the managed layer, but they typically leave credentials, sandboxing, state persistence, and provider routing to the application. A managed agent layer in the sense used here owns all of those, and runs them as platform infrastructure rather than as code inside the agent's process.
What are the alternatives to a managed runtime, and when are they better?
The big ones, in rough order of how different they are:
This post advocates one architecture. None of these are wrong; they sit at different points on the same flexibility-vs-operational-consistency curve.
What are the downsides of a managed runtime?
Four worth being honest about. (1) Less local flexibility — agent code cannot reach around the runtime to do clever per-tool credential handling or custom retry policies. (2) Harder experimentation — running an agent locally now requires the runtime to be available, not just a Python interpreter. (3) Runtime lock-in — moving an agent off the runtime is a real migration, not a recompile. (4) Abstraction leakage when something goes wrong — debugging a failed agent now involves reasoning across the agent's reasoning, the runtime's orchestration, and the gateways underneath, with three log streams to correlate. The article argues these are usually worth paying past the third or fourth production agent; for the first one, they often aren't.
If Anthropic ships managed agents as a product, why build your own?
For agents that live entirely on Claude, Anthropic's managed-agents product is usually the simplest path. The cases where teams build their own typically come down to multi-provider routing (running the same agent against different models for different workloads), workload-specific sandboxing (a self-hosted gVisor pool for untrusted code), or integration with existing platform infrastructure (a corporate secrets manager, an existing observability stack). The pattern is the same; the question is what's bought vs. assembled.
How does this work for agents that don't execute code?
The sandbox component is optional. A pure tool-using agent — one that orchestrates MCP calls and produces structured output — doesn't need code execution, and the runtime can skip the sandbox entirely. The other four components (orchestration, state, credentials, retry) still apply.
What does the runtime look like for streaming responses or partial outputs?
The llm() API exposes both batched and streaming variants. For streaming, agent code receives an async iterator of chunks; the runtime handles the underlying provider stream, applies output guardrails as chunks arrive, and emits per-turn OTel spans on stream close.
How is this tested? You can't unit-test something that depends on an LLM and a sandbox.
The managed layer is what makes agents testable. The three APIs (call_tool, llm, save_state/load_state) are the agent's entire dependency surface, and each can be mocked or replayed. A test suite typically pairs a deterministic mock-llm with recorded tool responses, so the agent's reasoning loop can be exercised without touching a provider or a sandbox. The runtime itself is tested separately, at the platform layer.
Where does TrueFoundry fit?
The TrueFoundry AI Gateway and MCP Gateway provide the inference and tool runtime layers of the architecture described here — model routing with provider fallback, guardrails, cost attribution, and budgets on the AI side; OAuth handling, RBAC, virtual MCP servers, and audit logging on the tool side. The orchestration, sandbox, and state-store layers above them are deliberately platform-team-owned, because that is where workload-specific decisions live. For teams that want a fully vertical managed product on Claude, Anthropic's Managed Agents is the right comparison.
The practical first step, for a team that has written its third or fourth agent and recognized the pattern in Devi's PR, is to extract the call_tool / llm / save_state surface into a small shared library and route each one through the gateways the platform already runs. Credentials and per-tool auth are owned by the runtime from the start, never plumbed through agent code. Everything else follows from that contract.
Northwind, Devi, and the four-agent codebase are illustrative; the architectural pattern, the entanglement problem, and the gateway-based decomposition are how production agent platforms are actually being built in 2026, of which Anthropic's Managed Agents is the most visible single-provider example. TrueFoundry's AI Gateway and MCP Gateway are real shipping products that supply the inference and tool runtime layers.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





