













Trusted by 1000+ Global Brands
Serve Any Model, Any Framework
Generative AI
Serve any Hugging Face model across text, image, multi-modal, and audio, with full support for OpenAI-compatible endpoints
Traditional ML
Effortlessly deploy and scale models built with XGBoost, scikit-learn, and LightGBM for reliable, high-performance predictions.
Deep Learning
Run production-ready models developed using PyTorch, TensorFlow, or Keras, optimized for speed, scalability, and stability.
Custom Containers
Deploy fully customized inference pipelines using your own Docker containers for complete control over runtime and dependencies.
RAG
Deploy embedding models, rerankers and vector databases to build accurate, context-aware AI applications.
Vision Models
Deploy and scale any computer vision model with ease, from image classification to advanced visual understanding.

Run Anywhere: Cloud, On-Prem, or Edge
- Fully cloud-native Kubernetes based deployments
- Deploy on AWS, GCP, Azure, on-prem, or at the edge
Effortless Auto-Scaling on CPUs/GPUs
- Supports both CPU- and GPU-intensive models
- Scale to zero or Autoscale on demand
.webp)

Secure & Controlled Access
- Fine-grained Role-Based Access Control
- Token based Authentication & API security
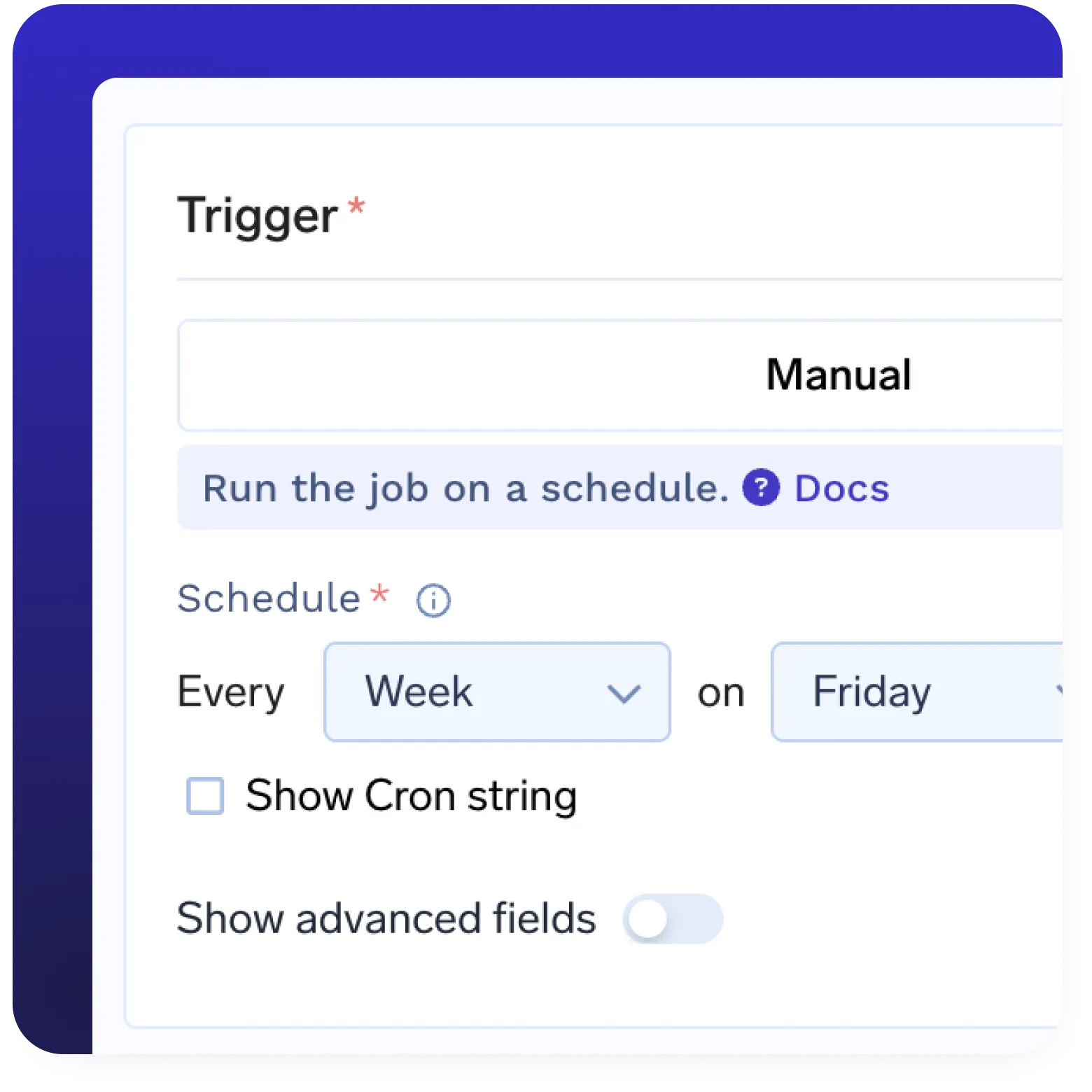
Batch & Streaming Inference
- Serve real-time predictions via REST or gRPC
- Schedule or trigger batch inference

Inbuilt Model Registry
- Inbuilt comprehensive model registry
- Auto-deploy models from registry
- Manage versions and metadata
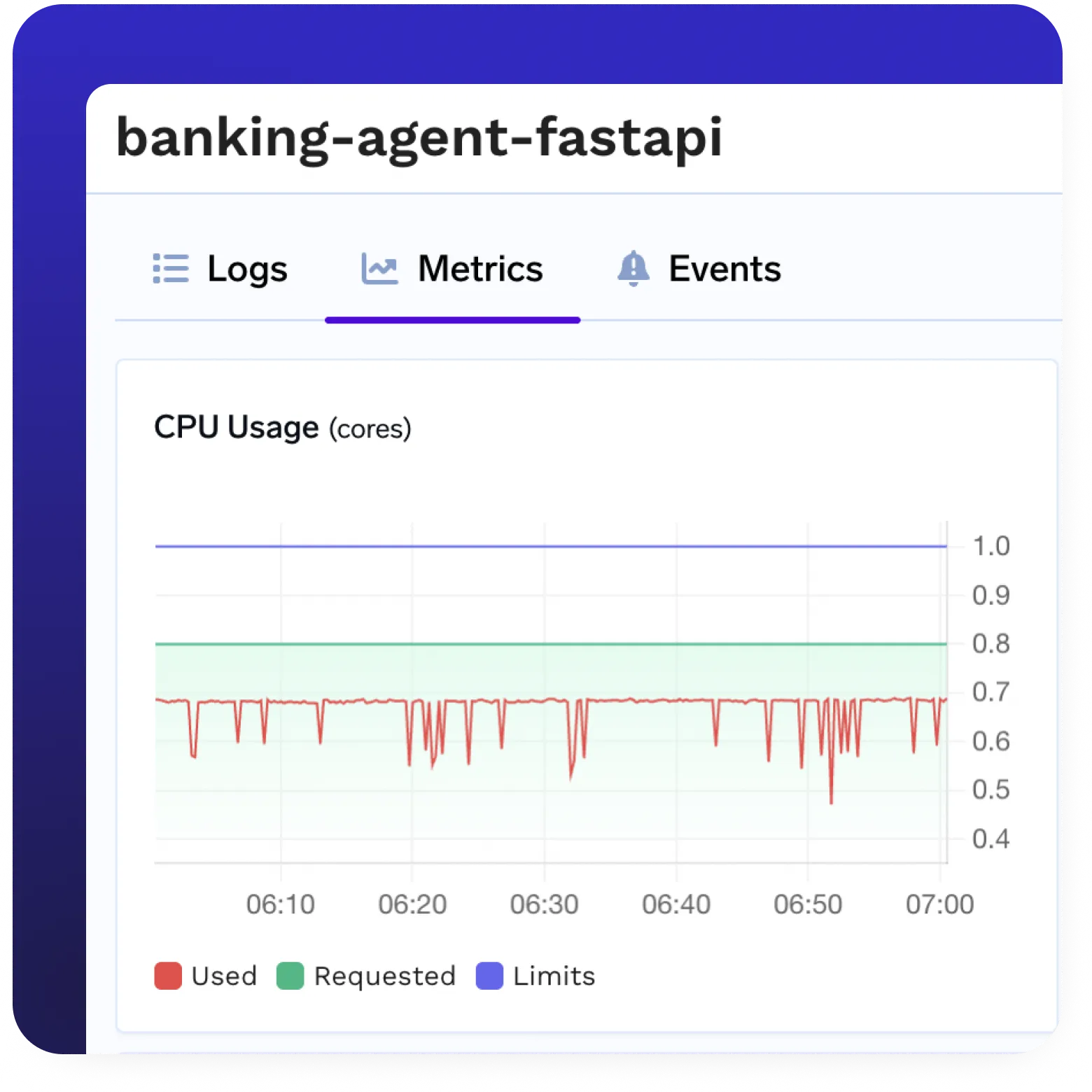
Full Observability & Monitoring
- Native support for Prometheus, Grafana, and OpenTelemetry
- Real-time logs, traces, and metrics
- Visibility across deployment, usage, and system health

Delightful Developer Experience
- Intuitive UI, SDK & CLI to manage, test, and monitor your models.
- Developer-first design from local dev to production.
Cost effective
- Intelligent infra optimization
- Efficient GPU utilization & spot instance support
- No vendor lock-in

Enterprise-Ready
Your data and models are securely housed within your cloud / on-prem infrastructure.

Fully Modular Systems
Integrates with and complements your existing stackTrue Compliance
SOC 2, HIPAA, and GDPR standards to ensure robust data protectionSecure By Design
Flexible Role based access control and audit trailsIndustry-standard Auth
SSO Integration via OIDC or SAML

GenAI infra- simple, faster, cheaper
Trusted by 30+ enterprises and Fortune 500 companies
Testimonials TrueFoundry makes your ML team 10x faster
.webp)
Deepanshi S
Lead Data Scientist



Matthieu Perrinel
Head of ML


Soma Dhavala
Director Of Machine Learning


Rajesh Chaganti
CTO


Sumit Rao
AVP of Data Science


Vivek Suyambu
Senior Software Engineer










