














July 18, 2026
|
5 min read

Published: April 16, 2026

Blazingly fast way to build, track and deploy your models!
It is your company’s internal AI hackathon, and one participant’s coding agent gets stuck in an unintended retry loop. It keeps firing long-context requests to a high-cost model for hours.
Because the organizers handed out raw provider keys to every participant, there are no team-level controls on spend or request velocity. By Monday morning, one runaway workflow had consumed a huge chunk of the shared LLM budget and pushed the organization into rate-limit pain.
That story lands because it is plausible. But the real lesson is broader: the right enterprise pattern for a hackathon is not distributing raw provider credentials and hoping teams behave. It is routing every request through a governed gateway that can separate teams, attach policy to metadata, and keep experimentation inside a controlled operating model.
TrueFoundry is a strong fit for that pattern because it combines Kubernetes-native workspace boundaries, secret indirection, metadata-aware policy controls, agent guardrails, and a gateway-native playground. The more precise claim is not that it guarantees ‘zero leaks’ or perfect hard-stop accounting under every burst pattern. The stronger and more defensible claim is that it gives platform teams a credible control plane for running hackathons without turning them into unmanaged cost and security events.

The first rule of a secure hackathon is simple: participants should never need to see the raw provider API keys. Once a key is copied into notebooks, local environments, or agent config files, it becomes both a security problem and a billing problem.
TrueFoundry’s workspace model helps here because workspace isolation maps to Kubernetes namespace boundaries. In practice, that means workloads for one workspace run in a different namespace than workloads in another workspace, and provider credentials can be exposed through secret groups and secret FQNs rather than pasted directly into app manifests or source files.
That is the right architecture for hackathon teams. Give each squad a workspace, give workloads access only to the secret groups they need, and keep the actual provider credential under platform control the entire time. The user experience is still simple, but the blast radius is smaller and auditable.
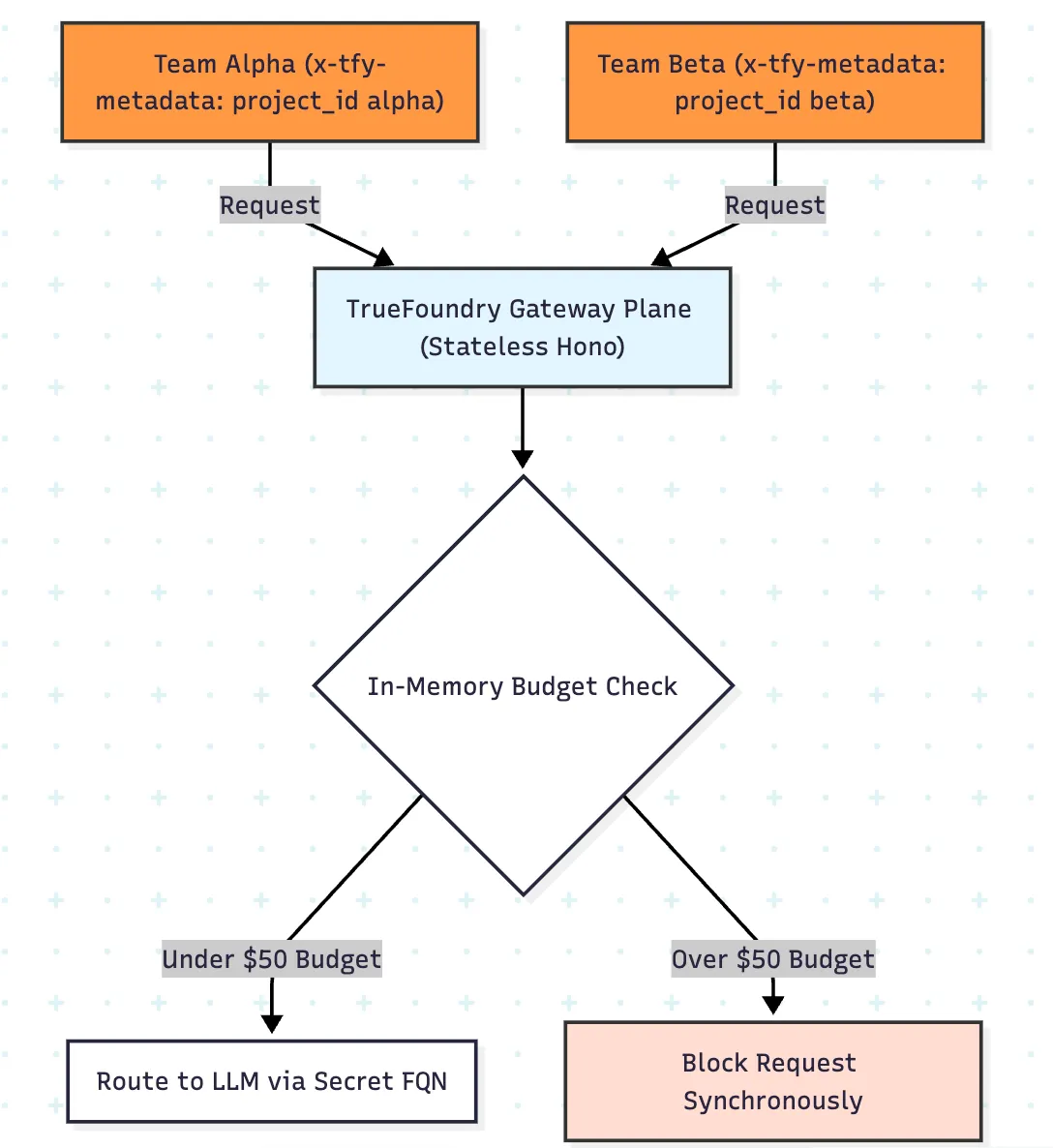
The most important operational question in an AI hackathon is not whether you can see spending after the fact. It is whether the platform can evaluate policy on the request path before a runaway workload gets expensive.
TrueFoundry’s gateway plane evaluates authentication, routing, guardrails, rate limits, and budget policy on the hot path using in-memory state, which enables low-latency enforcement before model invocation. That is materially better than a design where the only reliable cost view arrives after logs are processed downstream.
The especially useful part for hackathons is metadata scoping. Instead of hand-authoring one rule per team, you can attach team identity in x-tfy-metadata and apply policy dynamically with fields such as metadata.project_id. That means one budget rule and one rate-limit rule can fan out into isolated counters and spend envelopes per team.
Hackathons are where teams try MCP servers, tool-calling agents, database connectors, and internal APIs. That is exactly where a traditional LLM-only security model starts to break down.
TrueFoundry’s guardrail model is especially relevant here because it exposes four execution points: LLM input, LLM output, MCP pre-tool, and MCP post-tool. That gives platform teams a more operational way to govern agents than relying on a single generic filter in front of the model.
The useful distinction is that different risks show up at different stages. Prompt injection may appear on the way in. Unsafe tool arguments appear before execution. Sensitive records may appear only after the tool returns. A four-hook model lets you place the right control at the right point in the flow.
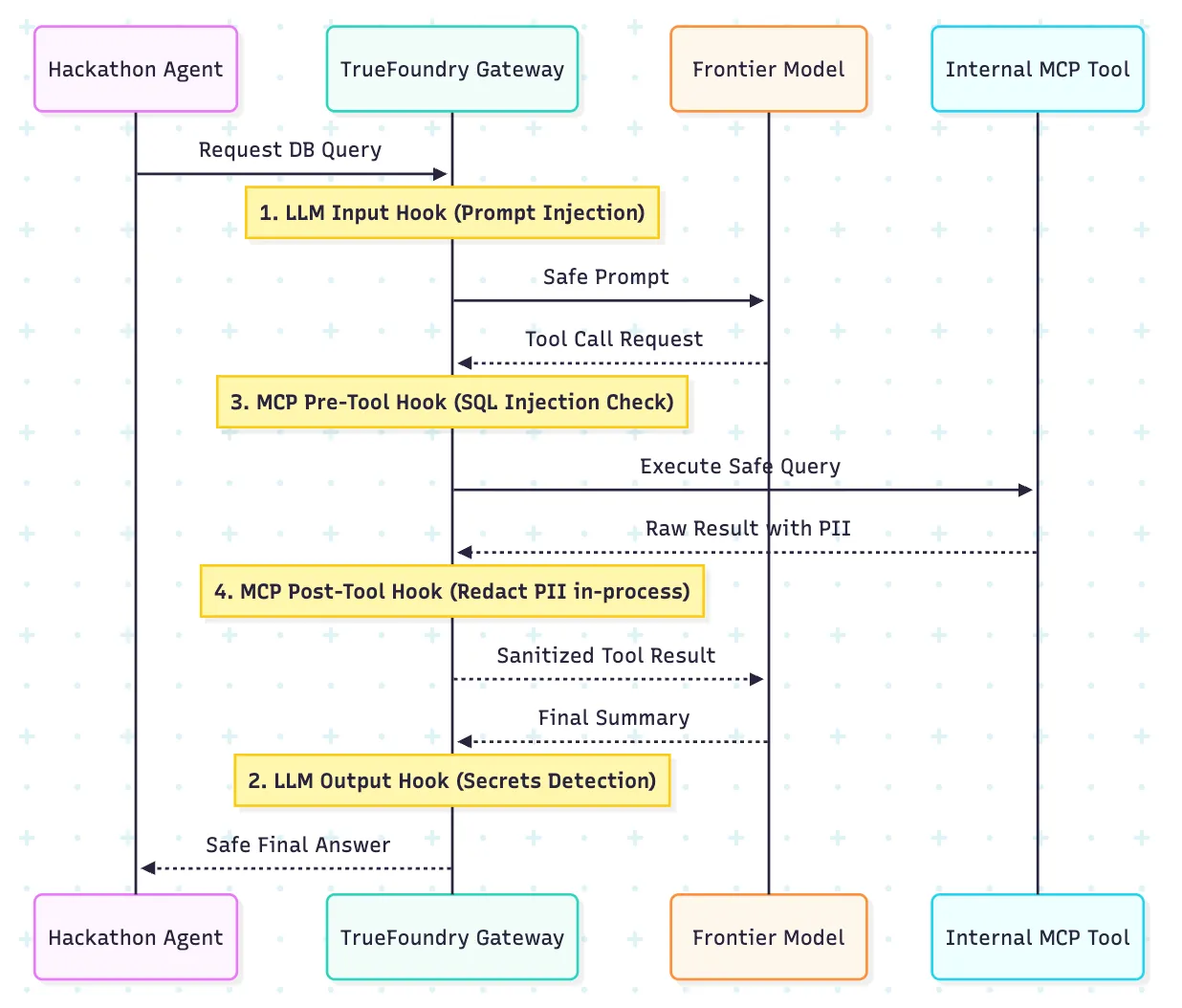
This is also where in-process detection matters. If secret scanning and related checks can run inside the gateway path without an extra outbound dependency, the control model is easier to reason about during a live event. Keep baseline guardrails common across teams, then layer stricter policies for teams using sensitive tools or datasets.
A secure hackathon still has to feel fast. If teams need a ticket every time they want to try a prompt, they will route around the platform. The answer is not less control. The answer is making the controlled path the easiest path.
This is where the gateway-native playground matters. The useful architectural point is that test traffic can flow through the same gateway plane used for production policies, so teams can validate prompts, routing, and guardrails in-loop rather than discovering policy behavior only after deployment.
The developer experience also gets better when the platform exposes response-level debugging signals. Headers such as x-tfy-resolved-model and x-tfy-applied-configurations, plus server-timing breakdowns, help teams understand what actually happened on a test request instead of guessing whether a fallback, guardrail, or routing rule fired.
Enterprise readers will push back immediately if a post over-promises on data residency. They should. The useful claim is not that every deployment is magically ‘air-gapped.’ It is that the split-plane design lets teams run the gateway plane on their own infrastructure while keeping the hot path for inference, policy checks, and model access under tighter operational control.
The other half of the story is observability. A hackathon is easier to manage when the platform team can see traces, latency, and policy behavior quickly. But observability is also a data-governance surface. If prompt or response data is exported for analytics, that needs to be an intentional choice with the right retention and destination controls.
The residency story gets stronger when you describe deployment mode, logging behavior, and export paths explicitly. That builds more trust than saying ‘zero leak’ and hoping the reader does not ask follow-up questions.
Yes - adding an explicit owner workflow is a good idea. It turns the post from architecture commentary into an execution guide.
1. One week before the event: define the control model
Create one workspace per team or per competition track. Decide the allowed models, the default provider path, the per-team budget, the per-team rate limit, and which teams may use MCP tools or sensitive internal data.
2. Before kickoff: preload the safe path
Publish a small starter kit for participants: the gateway endpoint, the required metadata shape, example SDK snippets, and a short guide to the playground. Teams should begin from the governed path, not from raw provider dashboards.
3. At registration: assign every team a project_id
Make project_id the required metadata field from day one. That gives you clean spend segmentation, cleaner tracing, cleaner incident review, and less manual mapping later.
4. During build hours: monitor the event like a live system
Watch team-level spend, rate-limit pressure, and unusual trace patterns. The goal is to rescue teams early, not only to analyze failures later.
5. For agent teams: require tool review before broad access
If a team wants database access, MCP servers, or internal APIs, move them onto a stricter guardrail profile before you enable those tools. Agent experiments should graduate into more trust, not start there.
6. Before demos: force a final playground pass
Have each team validate its final flow through the playground or the official test surface. That catches missing metadata, unexpected routing, and guardrail surprises before demo time.
7. After the event: turn observations into platform defaults
Review the traces, budget incidents, blocked calls, and support questions. Then convert the best practices into default workspace templates, snippets, and policy baselines for the next hackathon.
The core thesis of the original post still works: if you are running an enterprise AI hackathon, the safest pattern is not handing out raw provider keys. It is routing requests through a gateway that can separate teams, meter spend, control throughput, and govern agent workflows.
What makes the revised version better is that it says this in a way a skeptical buyer can believe. TrueFoundry’s strongest hackathon story is not a vague promise of total safety. It is a practical combination of workspace isolation, secret indirection, metadata-scoped policy, governed agent hooks, request-path controls, and a playground that helps teams test through the same policy surface they will ship through.
That is enough. Your hackers still get to build the future. Your platform, security, and finance teams just do not have to lose a weekend in the process.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





