














July 18, 2026
|
5 min read

Published: May 29, 2026

Blazingly fast way to build, track and deploy your models!
Large language models have crossed an important threshold. What began as isolated experiments and pilot projects has now evolved into production workloads embedded across enterprise systems. Customer support, internal knowledge search, software development, analytics, and autonomous agents increasingly rely on LLMs as core building blocks rather than optional enhancements.
This shift has exposed a new class of infrastructure challenges. LLM workloads behave very differently from traditional application services. Costs scale with tokens rather than requests, latency varies significantly across providers and regions, and failure modes - timeouts, hallucinations, or partial responses are often opaque. As organizations adopt multiple models from different providers, these issues compound rapidly.
For most enterprises, early LLM integrations were built with direct API calls and application-level logic. That approach does not hold at scale. Teams quickly run into unpredictable inference costs, limited visibility into usage, provider lock-in, and growing governance concerns. Optimizing LLM workloads becomes increasingly difficult when each application implements its own routing, retries, cost controls, and logging.
As AI adoption expands horizontally across teams and vertically across environments, LLM workload optimization shifts from an application problem to an infrastructure problem. Enterprises need a centralized layer that can observe, control, and optimize how models are used consistently and at scale. This need has driven the emergence of AI gateways as a foundational component of modern AI infrastructure.
Optimizing LLM workloads is fundamentally different from optimizing traditional compute or microservices. The challenges are systemic, not localized.
First, cost dynamics are nonlinear. A small change in prompt structure, retry logic, or context size can significantly increase token consumption and spend. Without centralized visibility and structured LLM cost tracking solution, these changes often go unnoticed until costs spike. Application-level controls lack the global context required to enforce budgets or compare efficiency across teams and use cases.
Second, performance variability is inherent. This becomes even more visible during LLM inferencing, where Latency and throughput differ across models, providers, and regions, and they fluctuate based on load and availability. Hardcoding a single provider or model into an application creates fragility. When outages or rate limits occur, teams are forced into reactive fixes instead of proactive optimization.
Third, multi-model adoption introduces operational complexity. Enterprises increasingly use a mix of premium models for critical workflows and lower-cost models for high-volume or non-critical tasks. Managing this mix efficiently requires routing decisions that balance cost, quality, and latency, decisions that should not live inside application code.
Finally, governance and compliance pressures continue to increase. Organizations must enforce access controls, monitor usage, maintain audit logs, and ensure data residency across regions. These requirements cut across every AI workload and cannot be addressed effectively on a per-application basis.
Together, these factors make it clear that LLM workload optimization cannot be solved piecemeal. It requires a centralized control layer that has visibility into all AI traffic and the authority to enforce policies consistently.
AI gateways address this challenge by acting as the control plane for LLM workloads. Positioned between applications and model providers, an AI gateway centralizes how LLM requests are routed, observed, governed, and optimized.
Unlike traditional API gateways, AI gateways are purpose-built for the characteristics of LLM workloads. They understand model-specific behavior, token-based pricing, latency trade-offs, and the need for fine-grained observability. This allows optimization strategies to be implemented once at the infrastructure layer and applied uniformly across all applications.
At a high level, AI gateways enable LLM workload optimization by:
This architectural approach decouples application logic from model management. Developers focus on building AI-powered features, while platform teams retain control over performance, cost, and risk.
As enterprises scale their use of LLMs, this separation becomes critical. Without it, optimization efforts are fragmented, reactive, and difficult to sustain. With it, organizations gain a consistent, measurable, and repeatable way to run LLM workloads efficiently, regardless of how many models, teams, or applications are involved.
As organizations mature in their use of LLMs, optimization strategies are becoming more systematic and infrastructure-driven. By 2026, several patterns are emerging as standard practice among enterprises running LLM workloads at scale.
Rather than treating model selection as a fixed choice, enterprises are adopting cost-aware orchestration. In this model, AI gateways dynamically balance cost, quality, and latency based on the context of each request.
For example:
This approach allows organizations to optimize spend without compromising user experience. Over time, it also creates a feedback loop where real usage data informs better orchestration decisions.
Regulatory requirements and geopolitical realities are reshaping how AI systems are deployed. Enterprises are increasingly operating geopartitioned AI stacks, where LLM workloads are isolated by region to meet data residency, sovereignty, and compliance requirements.
In practice, this means:
AI gateways play a central role in enforcing these constraints while still providing a unified operational model across regions.
As LLM usage scales, organizations are moving away from repeatedly sending large contexts to models. Instead, they are adopting tool-driven AI systems, where models retrieve information on demand through controlled interfaces.
This shift:
AI gateways increasingly mediate not just model calls, but also tool and API execution, ensuring that AI systems interact with enterprise data in a controlled, auditable manner.
The rise of autonomous and semi-autonomous agents introduces new optimization challenges. Agents often make multiple model calls, invoke tools, and execute long-running workflows.
Leading organizations are extending optimization strategies to the agent layer by:
AI gateways are evolving to support this shift, acting as a mediation layer for both model inference and agent execution.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Choosing an AI gateway is not a tooling decision—it is an infrastructure commitment. For most enterprises, this layer will sit in the critical path of every LLM-powered application, making its design choices hard to reverse later. As a result, evaluation should focus less on surface-level features and more on architectural fit, operational maturity, and long-term flexibility.
Below is a practical framework technical executives can use to evaluate AI gateways specifically through the lens of LLM workload optimization.
A leading AI gateway should enable true multi-model usage without forcing applications to change when models or providers change.
Key questions to ask:
If model choice leaks into application logic, optimization will be slow and brittle.
LLM optimization is impossible without cost visibility. Gateways should provide insight and enforcement at the level where decisions are made.
Look for:
A gateway that only reports aggregate usage is insufficient for real optimization.
Because the gateway sits in the hot path, performance characteristics matter.
Evaluate:
Even a small performance penalty can compound at scale.
Optimization depends on feedback loops. The gateway should act as the system of record for LLM activity.
Assess whether the gateway provides:
If observability feels bolted on, optimization will be reactive rather than systematic.
Optimization must coexist with enterprise risk controls.
Key considerations include:
A gateway that requires trade-offs between optimization and compliance will not scale in regulated environments.
Finally, evaluate how the gateway fits into your existing infrastructure and operating model.
Consider:
The more tightly the gateway integrates with your platform stack, the easier it will be to operate long term.
TrueFoundry’s architecture is built around a clear premise: LLM workload optimization is an infrastructure concern, not an application responsibility. As a result, its AI Gateway is designed as a first-class control plane that sits at the center of the enterprise AI stack.
In a TrueFoundry deployment, applications and agents never interact directly with model providers. Instead, all LLM traffic flows through the AI Gateway, which acts as a single, stable interface for inference, routing, observability, and governance.
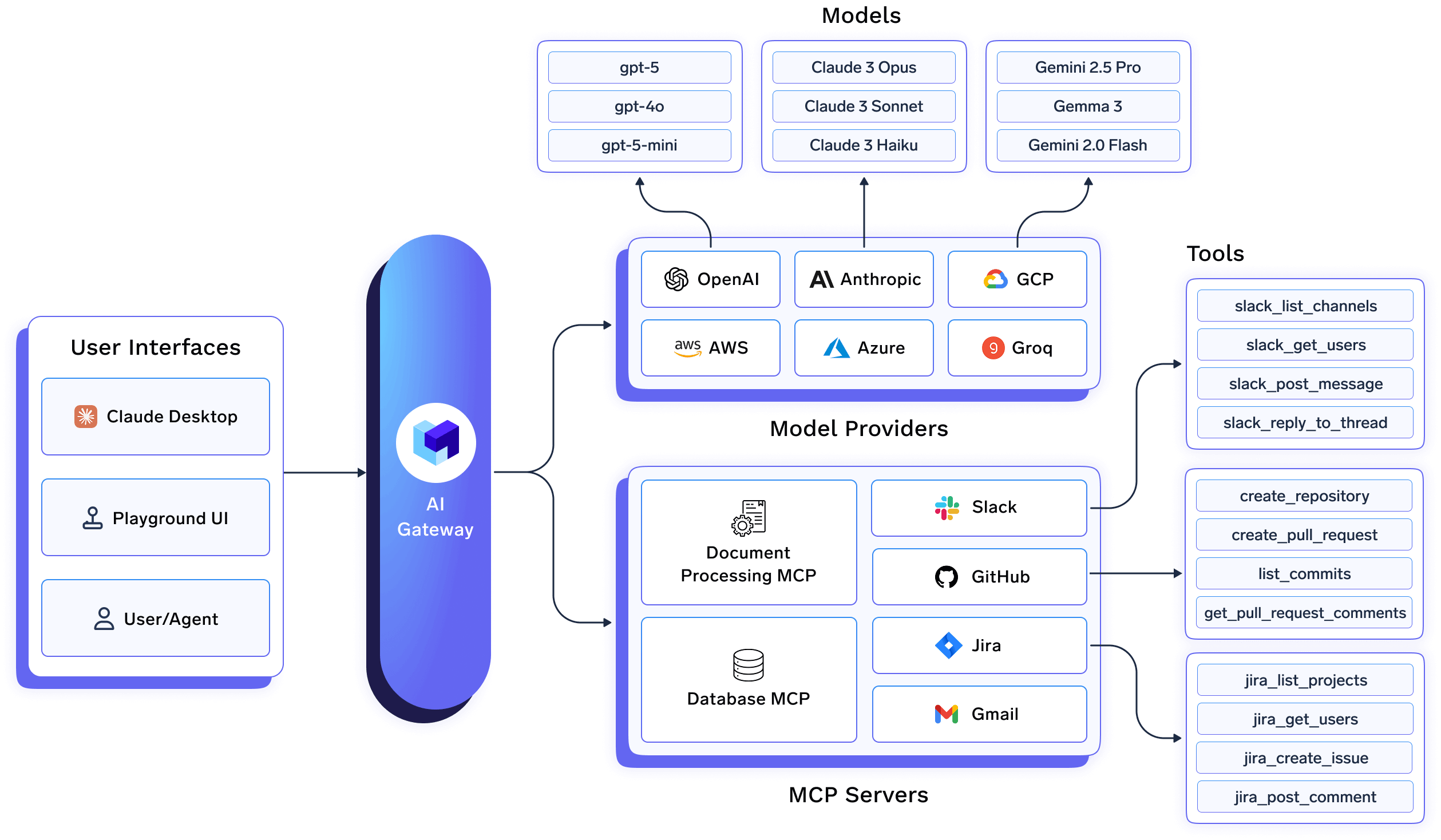
At an architectural level, this means:
This design removes model-specific concerns from application code and allows optimization strategies to evolve independently.
TrueFoundry’s AI Gateway enables true multi-model operation by abstracting provider-specific APIs behind a single contract. Routing decisions , such as which model to use, when to fall back, or how to balance cost versus latency are handled centrally at the gateway.
In practice, this allows platform teams to:
Because routing is handled at the gateway, changes to pricing, performance, or provider availability can be addressed immediately, rather than requiring application-level changes.
A core principle of TrueFoundry’s architecture is that the AI Gateway functions as the system of record for all LLM activity. Every request passing through the gateway is captured with detailed metadata, including model selection, token usage, latency, and request context.
Unlike many platforms that centralize this data in vendor-managed systems, TrueFoundry’s design ensures that:
This approach avoids the “black box” problem and enables organizations to build long-term optimization feedback loops using their own data.
TrueFoundry’s AI Gateway embeds cost and governance controls directly into the request path. Rather than relying on downstream billing reports or external tooling, optimization and enforcement happen in real time.
Key architectural capabilities include:
Because these controls are centralized, every LLM-powered application inherits them automatically. This makes it possible to scale AI usage across teams without duplicating governance logic.
TrueFoundry’s AI Gateway is designed to be deployed where enterprise data already lives. It can run in private VPCs, on-prem environments, or controlled cloud regions, enabling organizations to meet strict data residency and regulatory requirements.
Architecturally, this supports:
This design aligns with enterprises operating across jurisdictions, where data movement must be tightly controlled.
TrueFoundry’s gateway-centric architecture is also aligned with the shift toward agent-based AI systems. As agents increasingly orchestrate multi-step workflows and invoke tools or APIs, the gateway becomes the natural enforcement point.
Within this model, the AI Gateway can:
This positions the gateway not just as an inference layer, but as a broader execution control plane for intelligent systems.
The defining characteristic of TrueFoundry’s approach is that optimization, governance, and observability are implemented once at the infrastructure layer and reused everywhere. This reduces operational complexity, improves consistency, and allows organizations to scale LLM workloads without losing control.
The broader takeaway is that TrueFoundry’s AI Gateway is not positioned as an add-on, but as core AI infrastructure. By treating the gateway as a long-lived architectural layer, TrueFoundry aligns with how enterprises already think about critical systems such as API gateways, data platforms, and compute orchestration.
As LLM adoption scales, optimization is no longer a matter of prompt tuning or model selection—it is an infrastructure decision. Cost volatility, performance variability, and governance requirements demand a centralized control layer that can operate across models, teams, and applications.
AI gateways have emerged as that layer. By consolidating routing, observability, cost controls, and policy enforcement, they turn LLM optimization into a systematic capability rather than an ongoing operational burden.
Platforms like TrueFoundry reflect this shift by treating the AI Gateway as a core piece of enterprise AI infrastructure. For technical leaders, the message is clear: sustainable LLM scale depends less on choosing the right model, and more on building the right foundation to run them.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





