














July 18, 2026
|
5 min read

Published: February 5, 2026

Blazingly fast way to build, track and deploy your models!
In today’s AI-driven enterprises, robust AI safety measures and LLM compliance are critical. As companies integrate powerful large language models (LLMs) into business workflows, they need mechanisms to keep these models “on track” with organizational rules. AI guardrails serve this role – analogous to roadside barriers – by ensuring every AI interaction reflects the company’s standards, policies, and values. Guardrails work by automatically checking or transforming LLM prompts and responses to enforce security, privacy, and content policies. TrueFoundry’s AI Gateway embeds such guardrails at the core of the AI pipeline, validating requests and responses to guarantee safety, quality, and compliance. This article provides a technical overview of AI guardrails in the context of an AI Gateway. We define what guardrails are, explain how they function, highlight their essential components, and describe how organizations can implement them.
AI guardrails are rule-based controls and filters placed around generative AI systems to enforce enterprise policies. Guardrails help ensure an AI tool “works in alignment with organizational standards, policies, and values.” Practically, this means guardrails might mask or remove sensitive data (for data privacy), block disallowed topics (for content compliance), or validate output formats (for quality assurance).
In an AI Gateway (like TrueFoundry’s), guardrails are applied at two points: before a request is sent to an LLM (input guardrails) and after a response is returned (output guardrails). By intercepting both ends of the LLM interaction, guardrails ensure that every prompt and reply adheres to enterprise rules.
Examples of AI Guardrails in action:
In short, AI guardrails are the technical enforcement of AI governance policies, making sure “every request and response meets [the] organization’s standards for security, quality, and compliance”.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry’s AI Gateway enforces guardrails on both the input and output of every LLM call. Input guardrails run before a prompt reaches the model, performing tasks like masking personal data or filtering prohibited content. Output guardrails run after the model responds, checking for unsafe or disallowed content (and optionally correcting it).
Each guardrail rule can operate in two modes: validate (block) or mutate (modify). In validate mode, any detected violation causes the request or response to be blocked with an error, strictly enforcing compliance. In mutate mode, the guardrail automatically alters the content to remove or transform the issue (for example, redacting a phone number or replacing a banned word). This two-stage (input/output) and two-mode (validate/mutate) approach ensures that no sensitive or non-compliant data slips through the system.
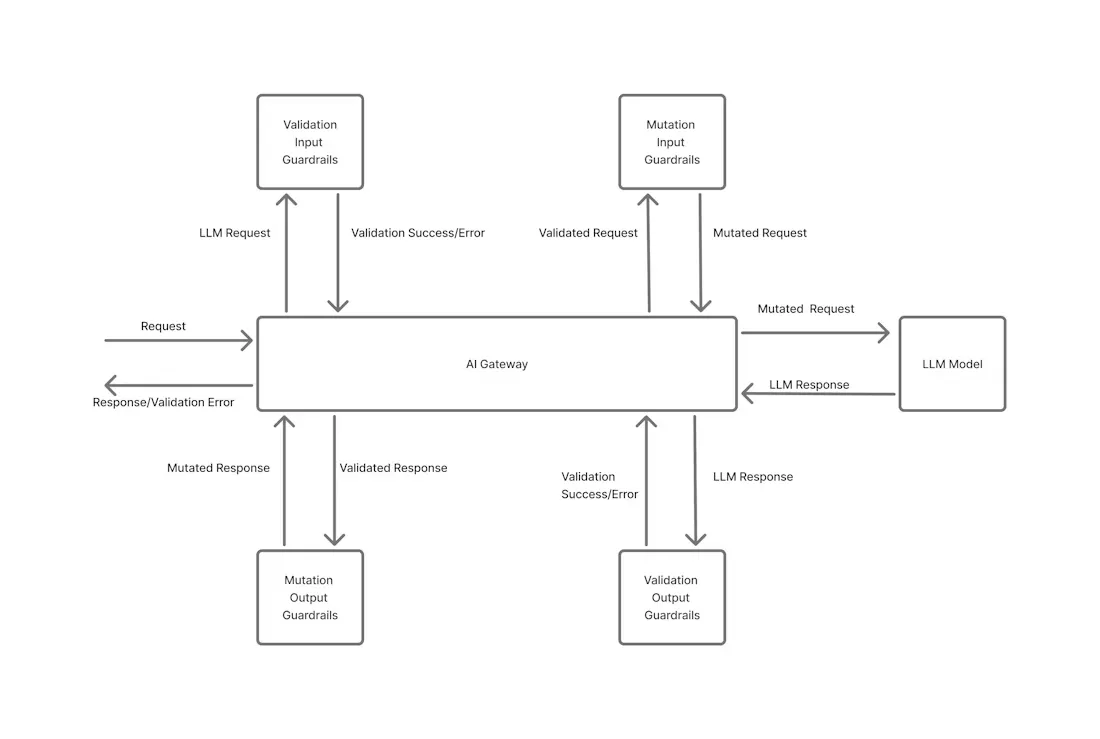
The diagram above illustrates how each message passes through the input filters before reaching the model and through output filters after the response, providing a safety net on both sides of the AI interaction.
TrueFoundry’s AI Gateway provides a unified control layer where enterprises can define, integrate, and manage guardrails across all LLM interactions—without modifying application logic. Guardrails can be configured declaratively via YAML, APIs, or the TrueFoundry Console, allowing teams to apply consistent policies across multiple AI providers (like OpenAI, Anthropic, or Azure OpenAI).
At a high level, guardrails are integrated at the Gateway layer, intercepting traffic between applications and the underlying LLMs.
This architecture ensures AI safety and compliance while maintaining low latency through parallelized execution and caching of guardrail results.
Developers and platform teams can configure guardrails at various scopes:
Global Guardrails: Organization-wide policies that apply to all models and endpoints (e.g., PII redaction or disallowed topics).
Model-Level Guardrails: Specific configurations per LLM provider (for instance, using Azure PII detection with GPT-4 but OpenAI Moderation for Claude).
Route-Level Guardrails: Fine-grained control at API routes—allowing different endpoints to enforce different validation or compliance rules.
A simple configuration example might look like this:

With TrueFoundry’s AI Gateway, organizations can integrate guardrails as a native part of their AI infrastructure, ensuring robust AI safety, data protection, and regulatory alignment—all while maintaining high performance and flexibility.
Without guardrails, enterprise LLM deployments face serious risks. Generative AI models can produce unpredictable or unsafe outputs that expose organizations to legal, reputational, and operational harm. For example, an unfiltered AI chatbot might inadvertently reveal personal user information or use profanity or biased language, eroding customer trust and potentially violating regulations like GDPR or HIPAA. In sensitive domains (e.g. healthcare or finance), even a single hallucinated answer could have disastrous consequences. Lack of real-time checks also means issues are detected only after deployment – for instance, by unhappy users or audit reviews – which is far costlier than catching them early.
In practice, the absence of guardrails leads to security breaches (data leaks), compliance violations (illegal advice or misinformation), brand damage (offensive or inconsistent responses), and unpredictable application behavior. In short, without guardrails to enforce AI safety and compliance, enterprises run the risk of costly mistakes and loss of control over their AI systems.
Effective AI guardrails combine several technical elements to cover different risk areas. A robust system typically includes:
(1) Rule Engine – an ordered set of policy rules that match on user, model, or context, ensuring only the first applicable rule fires
(2) PII & Data Filters – built-in or external detectors that recognize and redact personal and sensitive information (emails, SSNs, credit cards, etc.) in both inputs and outputs
(3) Content Classifiers – semantic filters that check for disallowed topics (medical advice, hate speech, profanity, etc.) or hallucinations against a taxonomy of risks
(4) Custom Keyword Filters – company-specific word or phrase blocklists that can transform or block particular terms in real-time and,
(5) Transformation Actions – the ability to either reject content (validate) or automatically sanitize it (mutate) based on policy.
In TrueFoundry’s platform, these components are implemented as “guardrail integrations” (for example, linking to OpenAI’s moderation API) which the Gateway invokes as needed. Each time a rule is applied, the system logs the event (what was checked, and how it was handled) for auditing and analysis. Combined, these features create a comprehensive safety framework: inputs are pre-scrubbed before they ever reach the LLM, and outputs are checked before they reach the user. In McKinsey’s terms, an effective guardrail system includes “checkers” to flag issues and “correctors” to fix them – exactly the role played by TrueFoundry’s input/output filters and transformation logic.
It is important to distinguish guardrails from governance. AI governance refers to the high-level frameworks, policies, roles, and oversight procedures that define what is acceptable and why – for example, an enterprise’s data privacy policy or AI ethics guidelines. Governance ensures that AI initiatives have clear accountability and align with legal and ethical standards. Guardrails, by contrast, are the technical enforcement mechanisms that implement those policies in real time on each AI request. In other words, governance sets the rules of the road, and guardrails are the barriers and sensors that keep the AI vehicle from veering off course. Having governance without guardrails means policies exist only on paper; having guardrails without governance means there is no clear guidance on what to enforce. In practice, effective AI risk management uses both: strategic governance defines the goals (e.g. “never reveal PII”, “no medical advice”), and guardrails (in the AI Gateway) automatically enforce those rules on every LLM interaction. As one analyst notes, organizations need both AI governance and technical guardrails working together to safely scale AI.
TrueFoundry’s AI Gateway makes it practical to deploy guardrails across an organization. Typically, administrators begin by creating a Guardrails Group in the Gateway UI – a container with defined managers and users – to hold policy integrations. Within that group, they add specific guardrail integrations (for example, OpenAI’s Moderation API for content filtering) by filling in the provider’s configuration form.
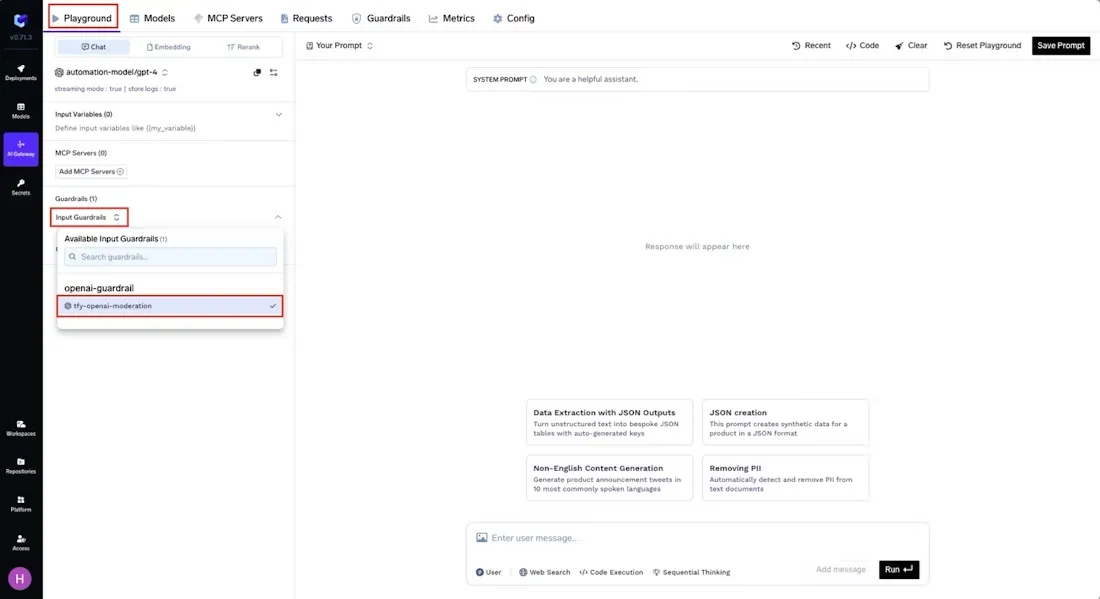
Once integrations are defined, teams can immediately test them using TrueFoundry’s Playground. For instance, one can apply an input guardrail and submit an unsafe prompt; the Playground will demonstrate that the guardrail blocks or sanitizes the content as expected.
In production code, developers can enforce guardrails per request by adding the X-TFY-GUARDRAILS header with the chosen rule set. This lets applications dynamically specify which filters to apply on a call-by-call basis.
For enterprise-wide policy, TrueFoundry supports gateway-level guardrail configurations: an administrator creates a YAML config in the AI Gateway’s Config tab specifying rules with when conditions and listing the input_guardrails and output_guardrails to apply. Only the first matching rule is used per request.
Defining guardrails at the gateway level is best for organization-wide enforcement, so that every AI request is automatically checked according to the company’s compliance standards. In this way, the AI Gateway centralizes guardrail management and auditing, eliminating the need to instrument each application separately.
The guardrails landscape is evolving rapidly alongside AI capabilities and regulations. Researchers advocate multi-layer guardrail architectures: for example, a primary input/output “gatekeeper” layer could be complemented by a knowledge-grounding layer that uses retrieval-augmented checks to verify factual accuracy. Organizations are also experimenting with intelligent guardrails – using AI agents to continuously monitor and correct model outputs in real time. On the tooling front, a growing ecosystem of open-source frameworks is emerging. NVIDIA’s NeMo Guardrails toolkit, LangChain’s Guardrails library, and others provide programmable rule engines for LLMs. Cloud providers likewise offer built-in moderation and safety filters for their AI services. Meanwhile, stricter regulations (such as the EU’s proposed AI Act) will drive demand for turnkey guardrail solutions that can demonstrate LLM compliance in real time. Overall, we can expect guardrails to become even more integrated into the AI development lifecycle – incorporating advanced NLP detectors, context-aware policies, and verifiable audit logs – to keep enterprise AI deployments both powerful and safe.
AI guardrails are essential for turning advanced LLMs from unpredictable experiments into reliable, compliant enterprise tools. By sandwiching every AI request between input and output checks, TrueFoundry’s AI Gateway enables organizations to enforce data privacy, content standards, and regulatory requirements automatically. The key is combining flexible, policy-driven filters (for PII masking, topic moderation, etc.) with real-time enforcement (validate or mutate actions) and thorough logging. For CTOs and AI architects, building in guardrails means unlocking generative AI’s potential without sacrificing trust or safety. In the enterprise context, robust guardrails at the gateway level are the backbone of responsible AI – they let businesses innovate confidently with LLMs, knowing that every response has been vetted against their security, quality, and compliance rules.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





